- 締切済み
pythonで桁の大きな数字を調べる方法
pythonですが、簡単なプログラムで計算しても10000!とかが計算できてしまいます。コンピュータで使える数字の桁数って限定されると思っていたのですが、pythonだと計算できるのでしょうか。 なお、ちゃんと計算できているのかどうか不明ではありますが。 また、ものすごく桁数が長い数字とか無理数とかですが、数字(0-9)が表れる頻度を調べることができないかと思いますが、プログラムを組むことは可能でしょうか。円周率でも平方根、ネイピア数とかでもですが。かなりイーブンになるものでしょうか。10000!とかだと原理的に0が多くなるようですが。 よろしくお願いします。

- skmsk1941093
- お礼率52% (611/1161)
- Python
- 回答数3
- ありがとう数2
- みんなの回答 (3)
- 専門家の回答
みんなの回答

- hue2011
- ベストアンサー率38% (2801/7249)
- cametan_42
- ベストアンサー率62% (166/266)
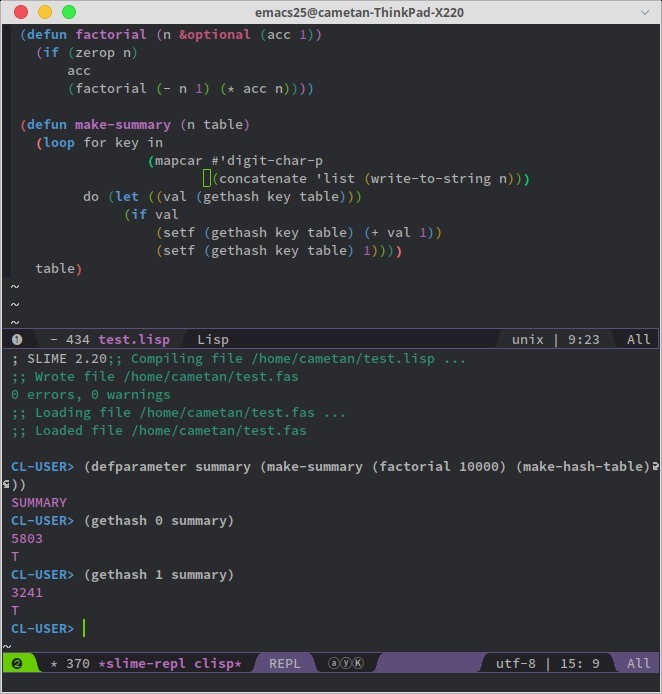
> pythonはFortran, Cなどの伝統的なプログラム言語とどこか一線を画するようなところがあるのでしょうか。 んー、伝統的かどうか、と言うより「ハードウェアに密接に関係している」か否か、って事でしょうね。Cはノイマン型計算機、要するに今主流のコンピュータですね、での「低レベルで効率的なプログラムを作成する為」設計されていて、効率重視、と言う意味ではFortranもそんなに変わらないでしょう。 Pythonは逆に「プログラミングしやすさ」「ロジック自体を(工学的理由に依らず)追求出来る」ように設計されています。ただ、これも方向性としては「伝統的」で昔からある考え方です。ただ、(Fortranがブイブイ言わせていた)当時と今と何が決定的に違うのか、と言うとハードウェアの処理速度がメチャクチャ速くなった、って事ですね。 Pythonのようなプログラミング言語は「実験室」の中には存在していましたが、市井のマシンは研究室で扱うような「大型コンピュータ」ではないので、それに比べると昔は低速でした。従ってPythonのようなプログラミング言語は「非効率的で非実用的」だった、と言う事です。ところが今はハードウェアが当時の大型コンピュータを凌駕するようなスピードを獲得してるので、「昔は非効率的と思われた」アイディアが、現在だと実用レベルになった、ってそれだけの話ですね。 注: 例えば、Javaは「JVM(Java仮想マシン」上で走るコードを生成するコンパイラ言語で、これがWrite once, Run anywhere(一度(プログラムを)書けば、どこでも実行できる)の理由になっていて、プラットフォーム毎に仮想マシンを用意しておけばどのマシンでもプログラム実行に問題がない環境を実現してる。 が、このアイディア自体は既にそれより20年程前のPascalで実現してて、実際元々Pascalは仮想マシン対象にコンパイルするプログラミング言語だった。つまり「仮想マシン」は別にJavaが「初めて」実現した方法ではない。しかしながら、大型コンピュータ用に元々作られたPascalを「仮想マシン」込みで民生機に持ってくるのはこれがなかなか「資源の無駄遣い」で、8bitパソコン黎明期を除き、仮想マシン対象のPascalは16ビット機以降殆ど使われなくなる(つまり直接機械語/アセンブリ言語に翻訳する処理系が中心となった)。 このように「アイディアが良くても」機械の処理速度が遅いと、民生機上で「実用的に使える」まで時間がかかる、と言うのは良くある事である。 例えば、「超」高級言語としてLispと言うプログラミング言語があります。例えばそのうち、Schemeと言う方言は1975年登場で、と言う事はC言語とほぼ登場時期が同じなんですが(C言語は1972年登場)、こいつも10000!なんかヘーキで計算しますね。 (define (factorial n) (let loop ((n n) (acc 1)) (if (zero? n) acc (loop (- n 1) (* n acc))))) (factorial 10000) 結果は桁数がものすごく多くなるんで、ここには載せませんが(笑)、こいつもPythonと同じように「ハードウェア資源が許す限り」どんな大きな数になってもヘーキで計算します。 (例えば https://download.racket-lang.org/ から処理系を入手してみて実験してみて下さい) これは要するにSchemeの言語仕様で「どんな大きな数になろうと正確な値を返せ」と要求しているから、です(そしてそれを実現する為のプログラミングはメチャクチャ大変ですね・笑。脱帽します)。 そして、伝統的かどうか、と言うより「PythonはCよりLispに近い」発想で設計されている、と言う事です。 > 無理数における数字出現率の傾向を調べるのはこれらの古典的言語でも簡単でしょうか。 任意の無理数さえ獲得すればそんなに難しくないでしょう。あとは、C言語やFortanで扱える「最大の整数」が何か、と言うのさえ把握していれば良いですよね。 つまり、プログラミングは言語によっては「ロジック」ともう一つ「工学上の理由」が要求される場合があって、C言語はその「後者」をケアしないといけない。一方、PythonやLispは後者を「考えなくて良い」ってのが違いで、とは言っても「ロジック」自体は要するに同じですよね。 例えば、前に見せたプログラム >>> import math >>> summary = {str(i):0 for i in range(10)} >>> for key in str(math.factorial(10000)): if key in summary: summary[key] += 1 >>> summary {'0': 5803, '1': 3241, '2': 3416, '3': 3258, '4': 3341, '5': 3324, '6': 3324, '7': 3335, '8': 3336, '9': 3282} >>> ってのは 1. カウントした「結果」を格納する為の変数summaryを作る(この場合はラベリングがあるのでPythonの辞書型を利用したが、C言語なんかは「長さが10の」配列を用意すれば良い)。 2. このケースの場合は10000!を計算し、結果を文字列に変換してる(C言語の場合でも文字列に変えられれば"数値を文字化した"「配列」を用意した事になる)。 3. 変換した文字列の頭から一文字一文字、「何の数値なのか」確認していって、変数summaryの対応する場所に+1していく。 つまり、「ロジック」自体はPythonでもLispでもC言語でも同じですね。別に変わらない。 ただ、PythonやLispだと「ロジックをそのまま記述すれば」プログラムは完成しますが、C言語なんかの場合だと 1. long型で10000!をそのまま計算出来るのか?計算「させる」為に何か特殊なプログラミングテクニックが必要にならないか? 2. 変数summaryの各格納庫の上限はint型やlong型で間に合うのか?10000!が何桁になるか分からないので、当然各格納庫の「上限」もどうなるか分からない。 3. 10000!をどうやって「配列化」するにせよ、その「配列」の長さがどうなるのかサッパリ分からない。 と言う問題が出てきますよね。ここはぶっちゃけ「ロジック」は全く関係なくって、「C言語を扱う上での工学上の問題」です。C言語だとこういう「工学的な壁」がアチコチ立ちはだかるので、結果C言語プログラミングはメンド臭くて厄介になるわけですね。 写真: 同じくLisp系言語Common Lispでの10000!の各数字(0~9)の出現率を調べるプログラム。 0が5803個、1が3241個ある、とPythonでの解と一致している。
- cametan_42
- ベストアンサー率62% (166/266)

















お礼
回答ありがとうございました。pythonはFortran, Cなどの伝統的なプログラム言語とどこか一線を画するようなところがあるのでしょうか。無理数における数字出現率の傾向を調べるのはこれらの古典的言語でも簡単でしょうか。こういう分野をやったことがないのでコード化を思いつかなったのですが。