- ベストアンサー
sedで文字列の一部を取り出す方法
- sedコマンドを使用して、文字列の一部を取り出したい場合、正規表現を使用してパターンを指定することができます。
- 提供された質問の例では、指定のファイルから特定のパターンを条件として抽出する方法を説明しています。
- ただし、正規表現のパターンが期待した結果を返さない場合、パターン自体や入力データのフォーマットを確認することが重要です。

- abc999xyz
- お礼率81% (173/213)
- Solaris系OS
- 回答数5
- ありがとう数5
- みんなの回答 (5)
- 専門家の回答
質問者が選んだベストアンサー

その他の回答 (4)

- M_Sato
- ベストアンサー率54% (550/1003)
以下のように、最初に後ろを切って、次にカンマから前を切ったらどうでしょう。これなら求めるデータがどの位置にあっても適応できると思います。 s/"\([A-Z0-9][A-Z0-9]*\)".*$/\1/;s/^.*,//
お礼
ありがとうございます。 たしかに、取り出したい文字列以降を捨ててしまえばできます
補足
>たしかに、取り出したい文字列以降を捨ててしまえばできます マルチステートメント? で、最初に後ろを切ってしまうということだったですね。 内容をよく確認せずまちがった返事でした。 マルチステートメント使えませんです。

- Wap58
- ベストアンサー率33% (29/87)
sed -r 's/.+?,"([A-Z0-9]+)",.+$/\1/' aaa 手元に実行環境ないけど これでいけんじゃないの?
お礼
ありがとうございます。 確認させてただきます。
補足
Linuxでためしてみましたが、できませんでした。 2番目が出力されます。

- asciiz
- ベストアンサー率70% (6870/9771)
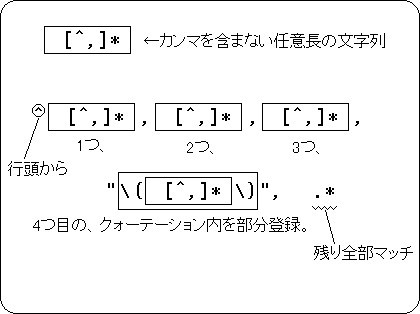
「.*」は、任意の文字、0文字でも何文字にでもマッチしてしまうので、安易に使ってはいけません。 特にマッチ文字列中でいくつも使うと、最初のものから最長になるようにマッチします。 今回の例では、最初の「.*,」の部分が「"aaa","bbb","ccc","123456","ddd","eee","fff",」にまでマッチするから、"0000"が取り出されてしまうというわけです。 さてそこで、任意文字にマッチしてしまう「.」ではなく、「カンマ以外」を示す「[^,]」を使ってみましょう。 sed 's/^[^,]*,[^,]*,[^,]*,"\([^,]*\)",.*/\1/g' aaa これで、カンマ区切りの「第4項目」を取り出せるんじゃないでしょうか。 まあ、文字列にカンマが含まれる場合はこれでも困りますけどね…。 sedはダブルクォーテーションの対応なんか気にしないので、項目区切りのカンマだろうが文字列中のカンマだろうが同一視してしまいます…。
お礼
ありがとうございます。 期待した結果となりました。 しかし、呪文のようですね。















お礼
ありがとうございます。 いろいろと方法を記載してありがとうございます。 1回ですましてしまおうとして、2回実行することには気がつきませんでした。 参考になります。